11 May
Hosting Laravel Application on EKS with Karpenter and KEDA
In this comprehensive guide, we will walk through the process of hosting a Laravel application on AWS EKS, leveraging Karpenter for autoscaling and KEDA for scaling SQS queues, which are fed by Lambda functions. This architecture allows for optimal resource utilization, high availability, and real-time processing of asynchronous tasks.
Prerequisites:
- An AWS account with EKS setup.
- kubectl and Helm installed.
- Karpenter installed and configured for autoscaling.
- KEDA configured for SQS queue scaling.
- Docker and Laravel application ready for containerization.
- AWS Lambda configured to send messages to SQS.
Architecture Overview:
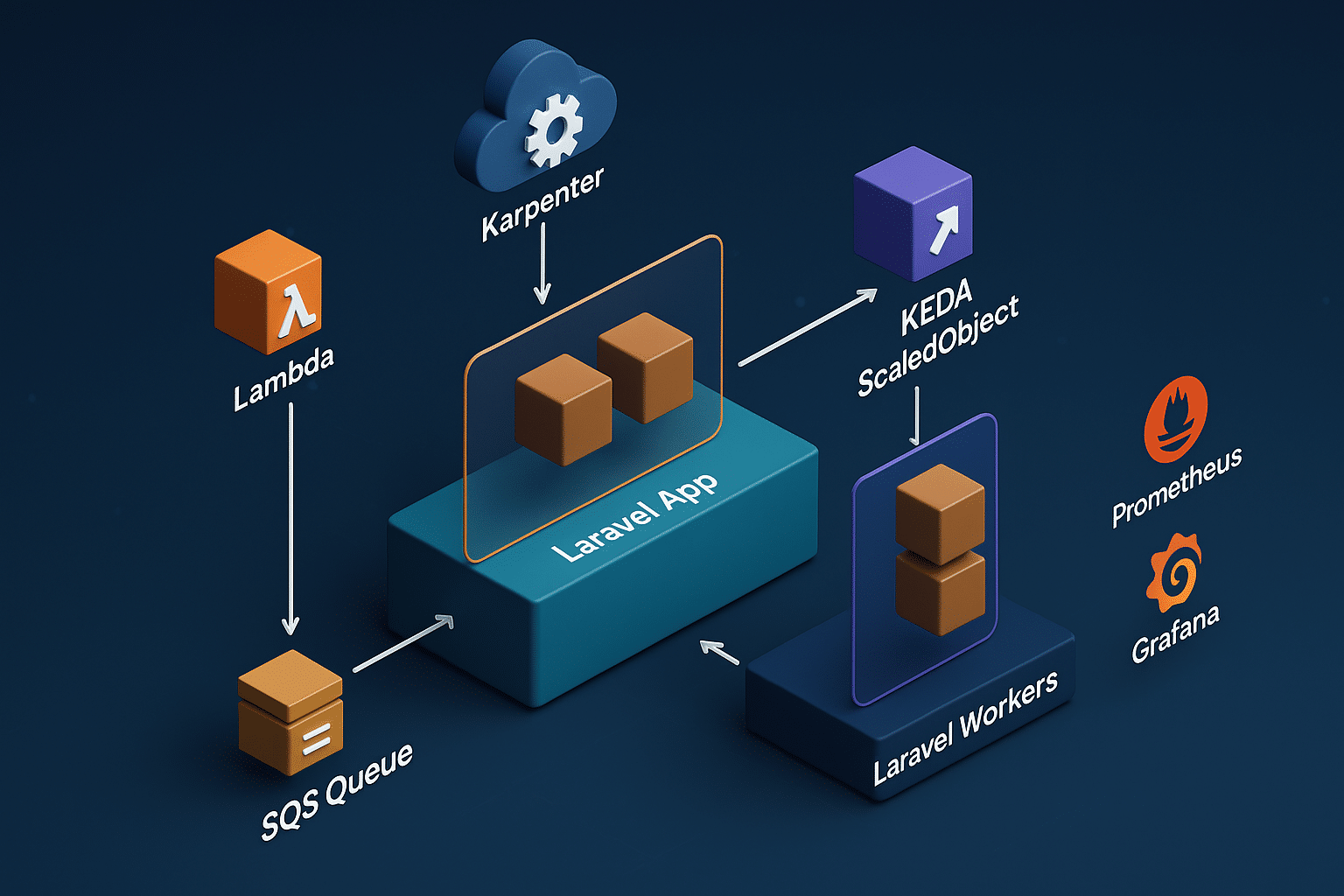
The diagram above represents the high-level architecture of deploying a Laravel application on AWS EKS, with Karpenter for auto-scaling, KEDA for scaling Laravel workers based on SQS messages, and Prometheus & Grafana for monitoring.
Key Components:
- EKS Cluster: Hosts the Laravel application in a scalable Kubernetes environment.
- Karpenter: Handles dynamic scaling of EKS worker nodes based on resource demand.
- KEDA: Monitors the SQS Queue and scales Laravel workers based on message count.
- SQS Queue: Manages asynchronous messages from the application and Lambda functions.
- Lambda Function: Triggers message delivery to the SQS Queue for background processing.
- Prometheus & Grafana: Provides real-time monitoring of application performance and scaling events.
This visual representation shows how each component interacts efficiently, optimizing cost and performance for high-availability Laravel applications.
The diagram above represents the high-level architecture of deploying a Laravel application on AWS EKS, with Karpenter for auto-scaling, KEDA for scaling Laravel workers based on SQS messages, and Prometheus & Grafana for monitoring.
Key Components:
- EKS Cluster: Hosts the Laravel application in a scalable Kubernetes environment.
- Karpenter: Handles dynamic scaling of EKS worker nodes based on resource demand.
- KEDA: Monitors the SQS Queue and scales Laravel workers based on message count.
- SQS Queue: Manages asynchronous messages from the application and Lambda functions.
- Lambda Function: Triggers message delivery to the SQS Queue for background processing.
- Prometheus & Grafana: Provides real-time monitoring of application performance and scaling events.
This visual representation shows how each component interacts efficiently, optimizing cost and performance for high-availability Laravel applications.
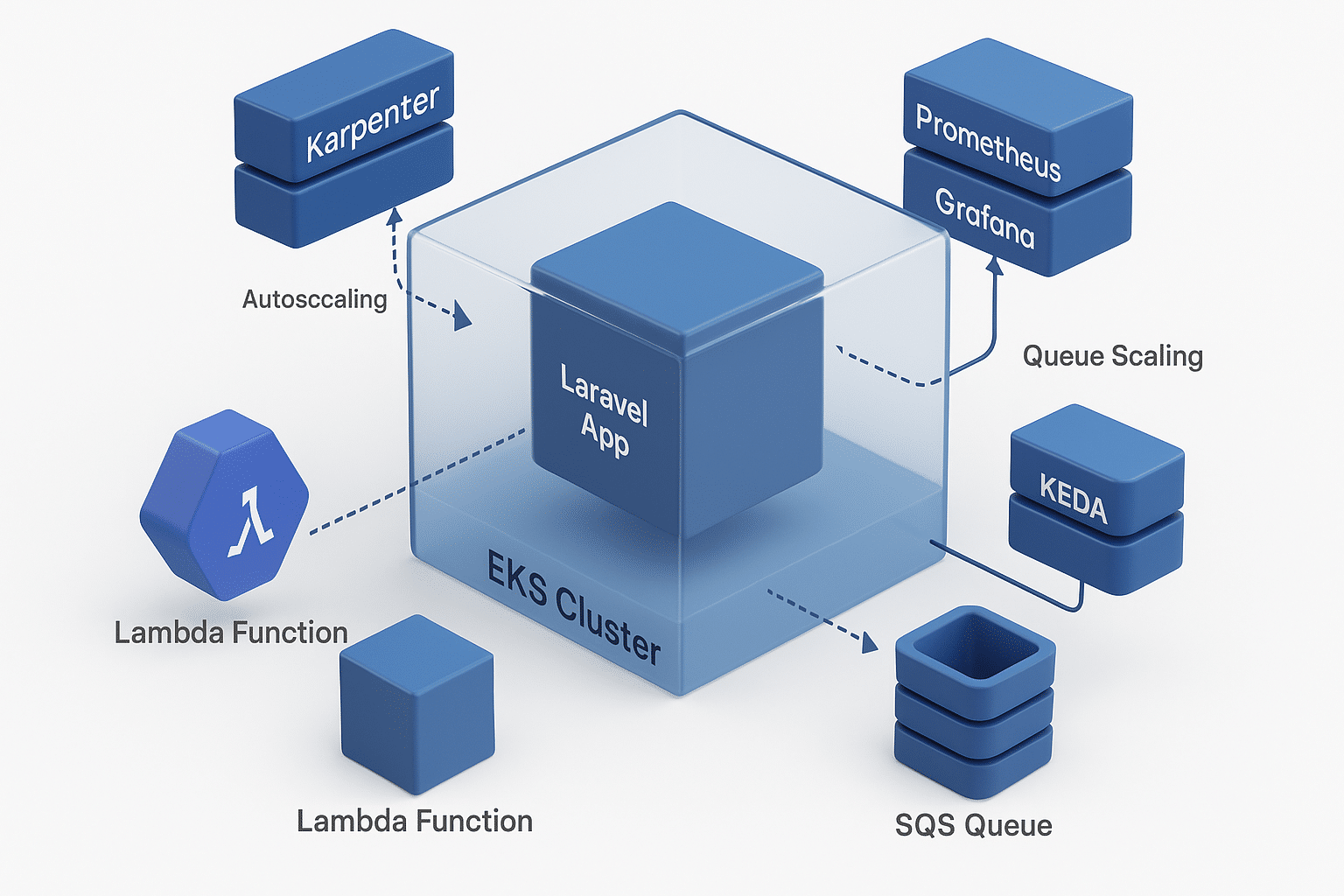
The architecture consists of the following components:
- EKS Cluster: Hosts the Laravel application in a scalable, managed Kubernetes environment.
- Karpenter: Provides efficient autoscaling for worker nodes based on workload demands.
- KEDA: Scales Laravel worker pods based on the number of messages in the SQS queue.
- SQS Queue: Acts as the message broker between Lambda and Laravel workers.
- Lambda Function: Sends messages to SQS, triggering Laravel job processing.
Step 1: Containerizing the Laravel Application
First, we need to Dockerize the Laravel application. Below is a sample Dockerfile:
FROM php:8.2-fpm
WORKDIR /var/www
COPY . .
RUN apt-get update && apt-get install -y \
libpng-dev \
libjpeg-dev \
libfreetype6-dev \
zip \
unzip
RUN docker-php-ext-configure gd --with-freetype --with-jpeg \
&& docker-php-ext-install gd pdo pdo_mysql
COPY --from=composer /usr/bin/composer /usr/bin/composer
RUN composer install --no-dev --optimize-autoloader
CMD ["php-fpm"]
Build the Docker image:
docker build -t laravel-app .
Push it to ECR:
docker tag laravel-app:latest <account-id>.dkr.ecr.<region>.amazonaws.com/laravel-app:latest
docker push <account-id>.dkr.ecr.<region>.amazonaws.com/laravel-app:latest
Step 2: Deploying on EKS
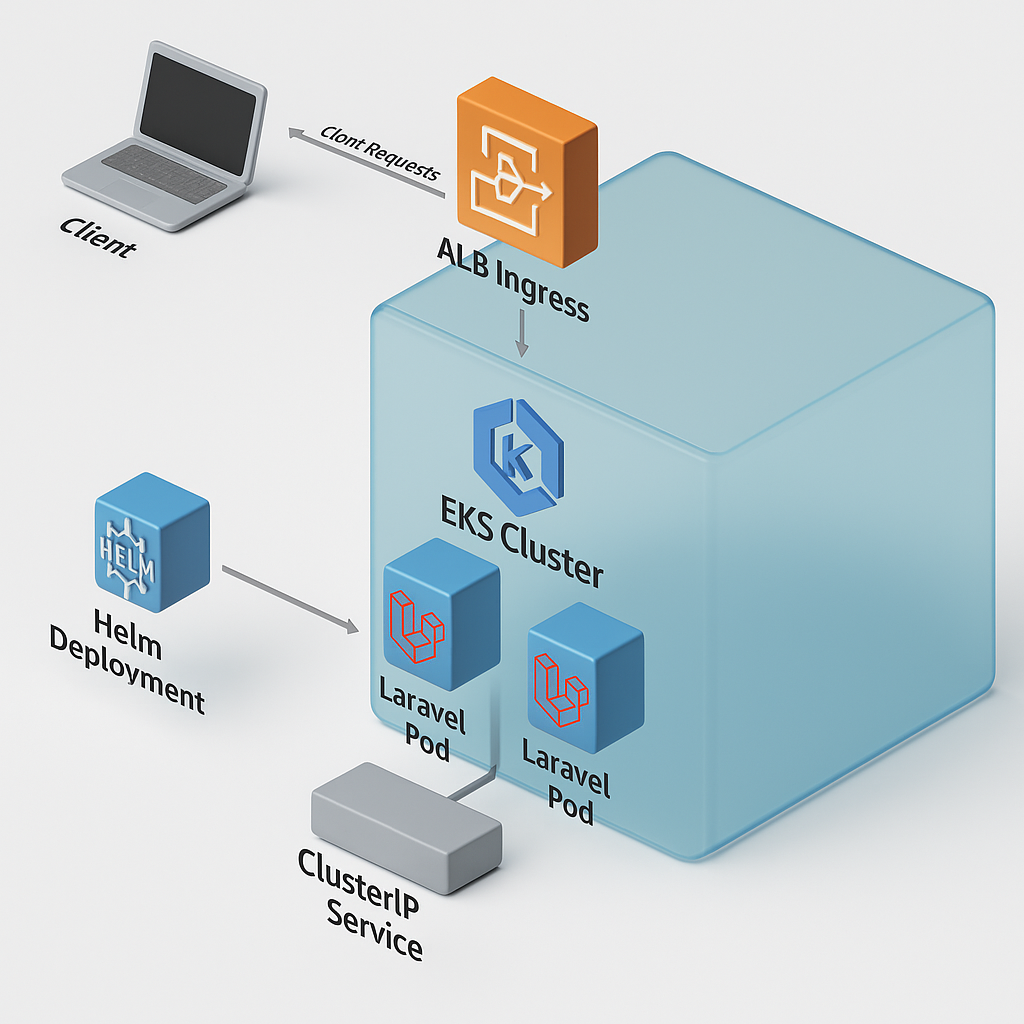
The diagram above represents the deployment process of the Laravel application on Amazon EKS using Helm and Ingress.
- Helm Deployment: Handles the configuration and release process to EKS.
- EKS Cluster: Manages containerized applications with high availability.
- Laravel Pods: Scaled and distributed pods running the Laravel application.
- ClusterIP Service: Exposes the Laravel application within the cluster.
- ALB Ingress: Manages external access to the application through routing and load balancing.
This deployment ensures that the Laravel application is accessible, load-balanced, and optimized for scalability.
The provided Helm charts include a well-structured setup for deploying Laravel applications in a Kubernetes environment. Here is an overview of the key Helm configurations:
replicaCount: 2
image:
repository: <account-id>.dkr.ecr.<region>.amazonaws.com/la### Step 2: Deploying on EKS

The diagram above represents the deployment process of the Laravel application on Amazon EKS using Helm and Ingress.
- **Helm Deployment**: Handles the configuration and release process to EKS.
- **EKS Cluster**: Manages containerized applications with high availability.
- **Laravel Pods**: Scaled and distributed pods running the Laravel application.
- **ClusterIP Service**: Exposes the Laravel application within the cluster.
- **ALB Ingress**: Manages external access to the application through routing and load balancing.
This deployment ensures that the Laravel application is accessible, load-balanced, and optimized for scalability.tPresent
tag: "latest"
service:
type: ClusterIP
port: 80
ingress:
enabled: true
annotations:
kubernetes.io/ingress.class: alb
hosts:
- host: laravel.example.com
paths:
- /
Step 3: Configuring Karpenter for Autoscaling
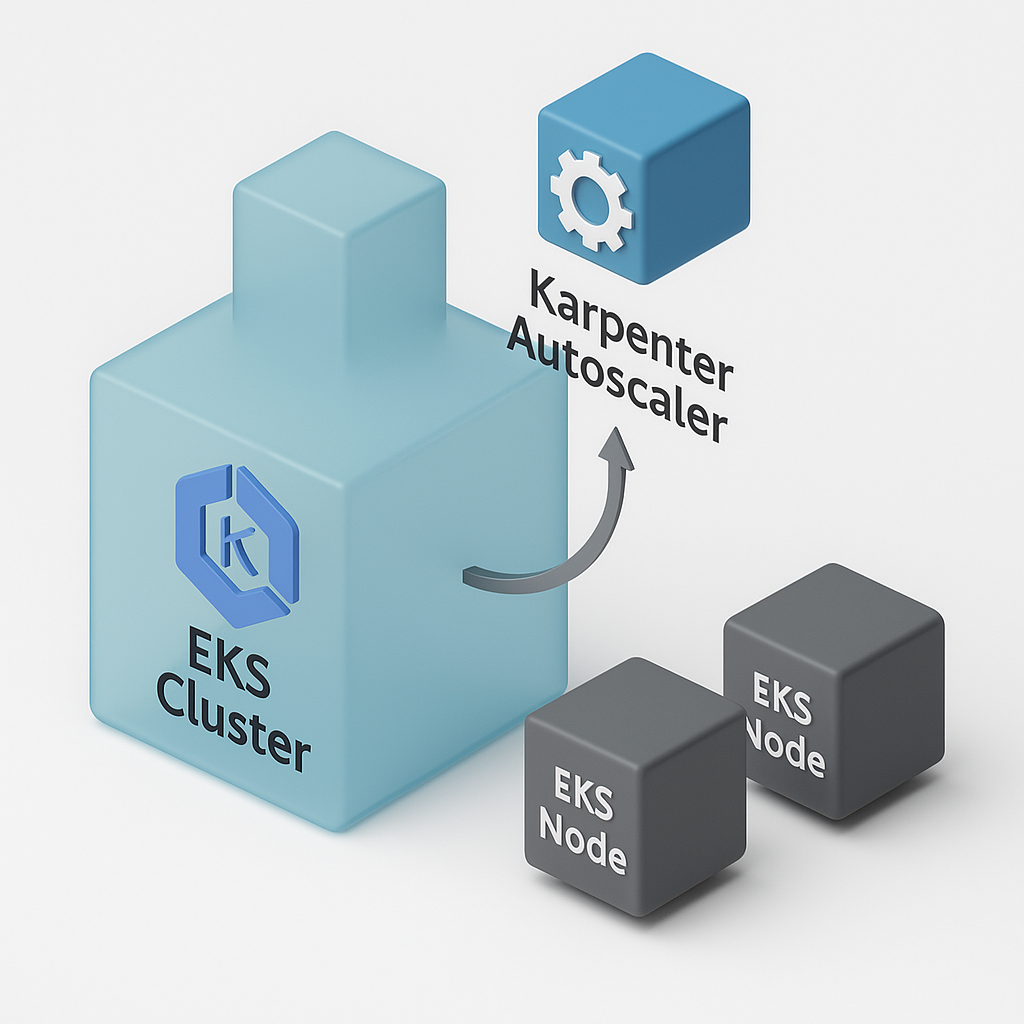
The diagram above illustrates how Karpenter manages the autoscaling of nodes within the EKS Cluster dynamically based on resource demand.
- EKS Cluster: The managed Kubernetes environment where applications are hosted.
- Karpenter: Automatically provisions or terminates nodes depending on the load.
- Node & Pod Management: As workload increases, Karpenter adjusts node capacity efficiently.
This mechanism ensures optimal resource usage, cost efficiency, and high availability for Laravel applications running on EKS.
The provided Helm values are optimized for dynamic scaling with Karpenter:
provisioners:
- name: default
requirements:
- key: "karpenter.sh/capacity-type"
operator: In
values: ["on-demand"]
limits:
resources:
cpu: "1000"
memory: "2000Gi"
Karpenter automatically scales the nodes based
Step 3: Configuring Karpenter for Autoscaling
The diagram above illustrates how Karpenter manages the autoscaling of nodes within the EKS Cluster dynamically based on resource demand.
- EKS Cluster: The managed Kubernetes environment where applications are hosted.
- Karpenter: Automatically provisions or terminates nodes depending on the load.
- Node & Pod Management: As workload increases, Karpenter adjusts node capacity efficiently.
This mechanism ensures optimal resource usage, cost efficiency, and high availability for Laravel applications running on EKS.DA for SQS Scaling

The diagram above showcases how KEDA scales the Laravel worker pods based on messages in the SQS Queue.
- SQS Queue: Stores job messages sent from the application or Lambda functions.
- KEDA: Monitors the queue length and scales Laravel worker pods accordingly.
- Worker Pods: Dynamically created to handle the load when more messages are in the queue.
This automated scaling ensures efficient resource utilization and responsiveness to varying loads.
We configure KEDA to monitor the SQS queue:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: laravel-worker-scaler
namespace: default
spec:
scaleTargetRef:
name: laravel-worker
triggers:
- type: aws-sqs-queue
metadata:
queueURL: https://sqs.<region>.amazonaws.com/<account-id>/laravel-job-queue
awsRegion: <region>
queueLength: "5"
Step 5: Step 4: Integrating KEDA for SQS Scaling
The diagram above showcases how KEDA scales the Laravel worker pods based on messages in the SQS Queue.
- SQS Queue: Stores job messages sent from the application or Lambda functions.
- KEDA: Monitors the queue length and scales Laravel worker pods accordingly.
- Worker Pods: Dynamically created to handle the load when more messages are in the queue.
This automated scaling ensures efficient resource utilization and responsiveness to varying loads.on Representation
The diagram above represents the Lambda to SQS Integration where Lambda functions asynchronously push messages to the SQS Queue.
- Lambda Function: Executes serverless logic to push job messages.
- SQS Queue: Receives the messages and queues them for processing.
This integration enables Laravel worker pods, managed by KEDA, to process jobs efficiently, ensuring seamless handling of real-time event-driven workloads.
Lambda functions push messages to the SQS queue, which KEDA then uses to scale the worker pods:
import boto3
sqs = boto3.client('sqs')
response = sqs.send_message(
QueueUrl='https://sqs.<region>.amazonaws.com/<account-id>/laravel-job-queue',
MessageBody='{"task": "process_order", "order_id": 1234}'
)
print(response)
Step 6: Monitoring and Autoscaling Validation
We use Prometheus and Grafana to monitor:
- Pod scaling
- Queue processing
- Step 5: Lambda Integration
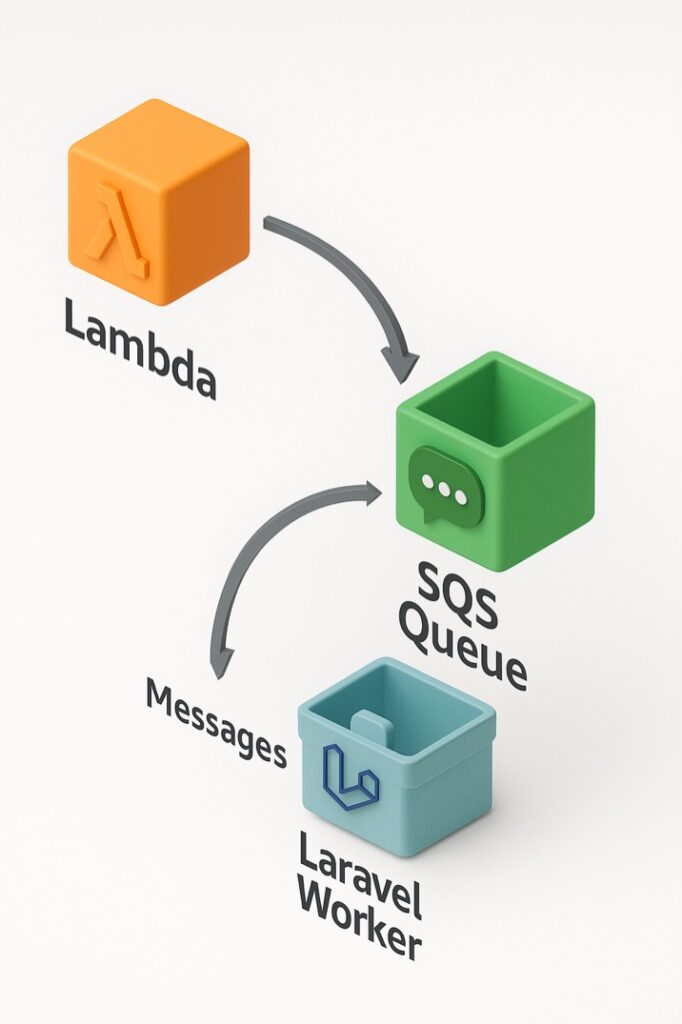
The diagram above represents the Lambda to SQS Integration where Lambda functions asynchronously push messages to the SQS Queue.
- Lambda Function: Executes serverless logic to push job messages.
- SQS Queue: Receives the messages and queues them for processing.
This integration enables Laravel worker pods, managed by KEDA, to process jobs efficiently, ensuring real-time event-driven workloads are handled seamlessly.vents
Conclusion
With this setup, your Laravel application is fully optimized for autoscaling using Karpenter for node management and KEDA for queue-based scaling. This architecture is cost-effective, resilient, and ready to handle fluctuating workloads seamlessly.
Next, we will deep dive into Helm chart optimizations and CI/CD pipeline configurations for zero-downtime deployments.


