24 Jan
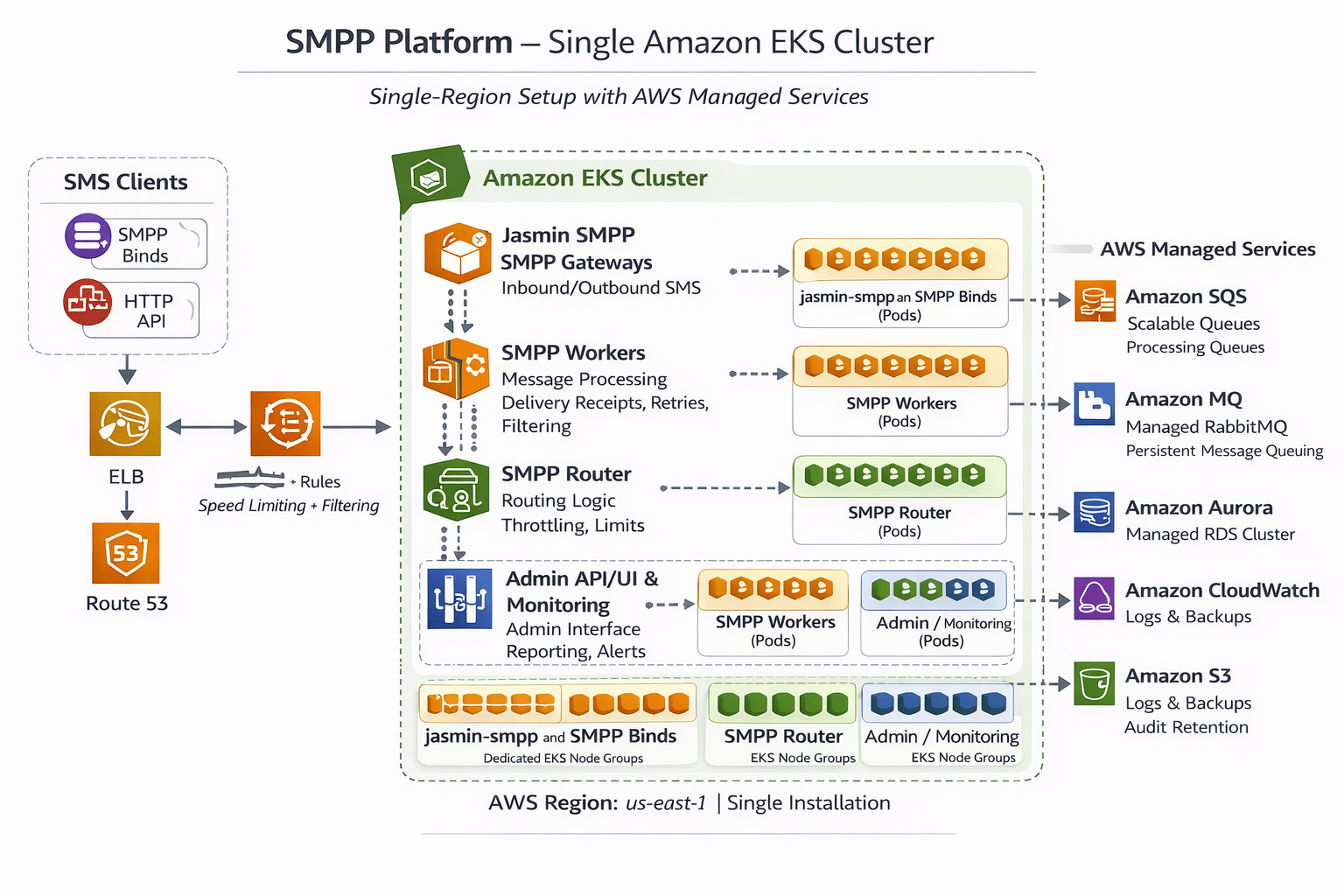
Running an SMPP platform at scale requires predictable throughput, controlled latency, resilient message handling, and clean operational boundaries between SMPP ingress, routing, asynchronous processing, and observability. The most practical approach for many teams is a single installation: one AWS region, one Amazon EKS cluster, and a set of AWS managed services to reduce operational overhead.
This post outlines a clear, production-grade architecture where SMPP components are deployed as separate Kubernetes Deployments inside one EKS cluster, while state and messaging are handled by managed AWS services.
High-Level Architecture
Traffic flow:
-
SMPP clients connect via TCP (commonly port 2775) to an AWS Network Load Balancer (NLB).
-
NLB forwards to Jasmin SMPP pods running in EKS.
-
Jasmin hands off work to router and worker services (also in EKS).
-
Messages, receipts, retries, and async jobs are buffered using Amazon SQS and/or Amazon MQ (managed).
-
Persistent storage and reporting live in Amazon Aurora (RDS).
-
Logs/metrics go to CloudWatch, long-term retention to S3.
This is not active-active and not multi-region. It is a single-cluster design with clear separation through Kubernetes objects.
Core EKS Deployments (Clear Component Separation)
A common failure mode in SMPP systems is mixing everything into one monolithic service. Instead, use separate Deployments, each with its own scaling, resource limits, and rollout strategy.
1) Deployment: jasmin-smpp-gateway
Purpose: SMPP ingress and bind management
Why separate: SMPP TCP handling has distinct scaling and connection constraints
-
Exposed via Kubernetes Service of type
LoadBalancer(backed by NLB) -
Scaled by connection load and CPU
-
Can be isolated to dedicated nodes using taints/tolerations if needed
2) Deployment: smpp-router
Purpose: Routing logic, throttling policies, connector selection
Why separate: Routing rules change often and should be deployable independently
-
Reads routing rules from Aurora (or config store)
-
Applies rate limits and policies per customer/connector
-
Sends async work to SQS/MQ
3) Deployment: smpp-workers
Purpose: Async processing (submit_sm, retries, DLRs, filtering, enrichment)
Why separate: Workers scale horizontally and should not impact ingress stability
-
Consumes from Amazon SQS (recommended for elastic queueing) and/or Amazon MQ (when you require broker semantics)
-
Scales using KEDA (queue depth-driven autoscaling) or HPA
4) Deployment: dlr-processor
Purpose: Delivery receipts (DLRs), callback webhooks, final state updates
Why separate: DLR spikes can be large and must not backpressure ingress
-
Writes final message status to Aurora
-
Optionally pushes delivery updates to customer endpoints via async queue
5) Deployment: admin-api
Purpose: Management API for customers, binds, rules, reporting, provisioning
Why separate: Admin/API release cycles differ from SMPP runtime components
-
Auth via IAM Identity Center / Cognito (depending on your approach)
-
Talks to Aurora and publishes jobs/events
6) Deployment: monitoring-exporters
Purpose: Metrics, probes, dashboards
Why separate: Keeps observability changes independent and stable
-
CloudWatch Container Insights / Prometheus exporters (your choice)
-
Alerting on bind failures, error rate, queue lag, DLR lag
AWS Managed Services Used (Reduce Ops, Increase Reliability)
Amazon Aurora (RDS)
Use Aurora PostgreSQL or Aurora MySQL for:
-
Customer accounts, routes, bind configs
-
Message metadata, reporting tables
-
DLR final state
Why Aurora:
-
Managed backups and maintenance
-
High read scalability (read replicas) when reporting grows
Amazon SQS
Use SQS for:
-
Message buffering between gateway/router and workers
-
Backpressure protection when downstream is slow
-
KEDA-based autoscaling using queue depth
Why SQS:
-
Simple, highly scalable queueing
-
Excellent fit for worker fan-out and retries
Amazon MQ (Optional)
Use Amazon MQ when you need:
-
AMQP/JMS compatibility
-
Broker features your ecosystem depends on
If you do not explicitly require broker semantics, SQS is typically simpler at scale.
Amazon CloudWatch
-
Centralized logs for ingress/router/worker components
-
Alarms for: bind disconnect spikes, error rates, queue backlog, latency
Amazon S3
-
Long-term log retention and audit trails
-
Exported reports, message archives, compliance artifacts
Scaling Strategy (Single Cluster, Predictable Scaling)
Jasmin SMPP gateway scaling
-
Scale based on CPU + connection metrics (where available)
-
Keep ingress stable by limiting per-pod connections
-
Use PodDisruptionBudgets to avoid mass disconnects during upgrades
Worker scaling
-
Use KEDA to scale workers from queue depth (SQS)
-
Separate worker types (submit_sm vs DLR vs retries) into distinct Deployments if needed
Router scaling
-
Usually lightweight; scale with CPU and request rate
Security and Network Baseline
-
NLB for SMPP TCP ingress (stable, high throughput)
-
Security groups restrict inbound SMPP ports to allowed networks
-
IRSA (IAM Roles for Service Accounts) for AWS access (SQS, CloudWatch, S3, Secrets)
-
Secrets stored in AWS Secrets Manager (recommended)
Why This Single-Cluster Approach Works
This design is effective because it:
-
Keeps the platform operationally simple (one installation)
-
Provides clear service boundaries via Deployments
-
Offloads persistence, queue durability, and retention to AWS managed services
-
Enables independent rollouts and scaling for each SMPP component
FAQs
Is this active-active?
No. This is a single EKS cluster installation in one region, with internal HA coming from Kubernetes replicas and AWS managed services.
Do I need Amazon MQ?
Only if your workloads require broker protocols/semantics (AMQP/JMS). For most SMPP async processing, SQS is sufficient and simpler.
Can I autoscale SMPP workloads safely?
Yes—by splitting gateway/router/workers into separate Deployments and using queue-driven autoscaling (KEDA) for workers.