14 Dec
[ad_1]
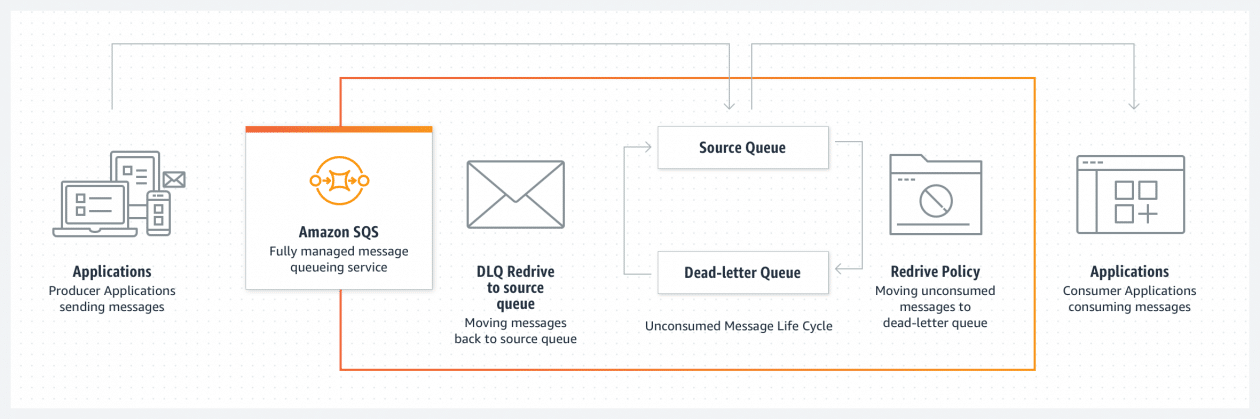
Hundreds of thousands of customers use Amazon Simple Queue Service (SQS) to build message-based applications to decouple and scale microservices, distributed systems, and serverless apps. When a message cannot be successfully processed by the queue consumer, you can configure SQS to store it in a dead-letter queue (DLQ).
As a software developer or architect, you’d like to examine and review unconsumed messages in your DLQs to figure out why they couldn’t be processed, identify patterns, resolve code errors, and ultimately reprocess these messages in the original queue. The life cycle of these unconsumed messages is part of your error-handling workflow, which is often manual and time consuming.
Today, I’m happy to announce the general availability of a new enhanced DLQ management experience for SQS standard queues that lets you easily redrive unconsumed messages from your DLQ to the source queue.
This new functionality is available in the SQS console and helps you focus on the important phase of your error handling workflow, which consists of identifying and resolving processing errors. With this new development experience, you can easily inspect a sample of the unconsumed messages and move them back to the original queue with a click, and without writing, maintaining, and securing any custom code. This new experience also takes care of redriving messages in batches, reducing overall costs.

DLQ and Lambda Processor Setup
If you’re already comfortable with the DLQ setup, then skip the setup and jump into the new DLQ redrive experience.
First, I create two queues: the source queue and the dead-letter queue.
I edit the source queue and configure the Dead-letter queue section. Here, I pick the DLQ and configure the Maximum receives, which is the number of times after which a message is reprocessed before being sent to the DLQ. For this demonstration, I’ve set it to one. This means that every failed message goes to the DLQ immediately. In a real-world environment, you might want to set a higher number depending on your requirements and based on what a failure means with respect to your application.

I also edit the DLQ to make sure that only my source queue is allowed to use this DLQ. This configuration is optional: when this Redrive allow policy is disabled, any SQS queue can use this DLQ. There are cases where you want to reuse a single DLQ for multiple queues. But usually it’s considered best practices to setup independent DLQs per source queue to simplify the redrive phase without affecting cost. Keep in mind that you’re charged based on the number of API calls, not the number of queues.

Once the DLQ is correctly set up, I need a processor. Let’s implement a simple message consumer using AWS Lambda.
The Lambda function written in Python will iterate over the batch of incoming messages, fetch two values from the message body, and print the sum of these two values.
import json
def lambda_handler(event, context):
for record in event['Records']:
payload = json.loads(record['body'])
value1 = payload['value1']
value2 = payload['value2']
value_sum = value1 + value2
print("the sum is %s" % value_sum)
return "OK"
The code above assumes that each message’s body contains two integer values that can be summed, without dealing with any validation or error handling. As you can imagine, this will lead to trouble later on.
Before processing any messages, you must grant this Lambda function enough permissions to read messages from SQS and configure its trigger. For the IAM permissions, I use the managed policy named AWSLambdaSQSQueueExecutionRole, which grants permissions to invoke sqs:ReceiveMessage, sqs:DeleteMessage, and sqs:GetQueueAttributes.
I use the Lambda console to set up the SQS trigger. I could achieve the same from the SQS console too.

Now I’m ready to process new messages using Send and receive messages for my source queue in the SQS console. I write {"value1": 10, "value2": 5} in the message body, and select Send message.

When I look at the CloudWatch logs of my Lambda function, I see a successful invocation.
START RequestId: 637888a3-c98b-5c20-8113-d2a74fd9edd1 Version: $LATEST
the sum is 15
END RequestId: 637888a3-c98b-5c20-8113-d2a74fd9edd1
REPORT RequestId: 637888a3-c98b-5c20-8113-d2a74fd9edd1 Duration: 1.31 ms Billed Duration: 2 ms Memory Size: 128 MB Max Memory Used: 39 MB Init Duration: 116.90 ms Troubleshooting powered by DLQ Redrive
Now what if a different producer starts publishing messages with the wrong format? For example, {"value1": "10", "value2": 5}. The first number is a string and this is quite likely to become a problem in my processor.
In fact, this is what I find in the CloudWatch logs:
To figure out what’s wrong in the offending message, I use the new SQS redrive functionality, selecting DLQ redrive in my dead-letter queue.

I use Poll for messages and fetch all unconsumed messages from the DLQ.

And then I inspect the unconsumed message by selecting it.

The problem is clear, and I decide to update my processing code to handle this case properly. In the ideal world, this is an upstream issue that should be fixed in the message producer. But let’s assume that I can’t control that system and it’s critically important for the business that I process this new type of messages.
Therefore, I update the processing logic as follows:
import json
def lambda_handler(event, context):
for record in event['Records']:
payload = json.loads(record['body'])
value1 = int(payload['value1'])
value2 = int(payload['value2'])
value_sum = value1 + value2
print("the sum is %s" % value_sum)
# do some more stuff
return "OK"
Now that my code is ready to process the unconsumed message, I start a new redrive task from the DLQ to the source queue.
By default, SQS will redrive unconsumed messages to the source queue. But you could also specify a different destination and provide a custom velocity to set the maximum number of messages per second.

I wait for the redrive task to complete by monitoring the redrive status in the console. This new section always shows the status of most recent redrive task.

The message has been moved back to the source queue and successfully processed by my Lambda function. Everything looks fine in my CloudWatch logs.
START RequestId: 637888a3-c98b-5c20-8113-d2a74fd9edd1 Version: $LATEST
the sum is 15
END RequestId: 637888a3-c98b-5c20-8113-d2a74fd9edd1
REPORT RequestId: 637888a3-c98b-5c20-8113-d2a74fd9edd1 Duration: 1.31 ms Billed Duration: 2 ms Memory Size: 128 MB Max Memory Used: 39 MB Init Duration: 116.90 ms Available Today at No Additional Cost
Today you can start leveraging the new DLQ redrive experience to simplify your development and troubleshooting workflows, without any additional cost. This new console experience is available in all AWS Regions where SQS is available, and we’re looking forward to hearing your feedback.
Check out the DLQ redrive documentation here.
— Alex
[ad_2]
Source link